Configuring joins by type
Siren Federate offers three join strategies: the hash join, the broadcast join, and the index join.
By default, the Siren Federate query planner selects the most cost-effective join strategy based on the scenario, but you can also manually select the strategy that you prefer.
About join strategies
-
The hash join is a fully-distributed join strategy that is designed to join a large number of documents. It scales horizontally (based on the number of data nodes) and vertically (based on the number of CPU cores).
-
The broadcast join is the strategy to use when you are joining a large set of documents (the parent set) with a small to medium set of documents (the child set).
-
The index join is the strategy to use when you are joining a large set of documents (the parent set) with a small set of documents (the child set).
When to use a hash join
The hash join is best suited to scenarios where both parent and child sets are large or when the child set is large. A large set is, for example, a set of ten million tuples or more.
The hash join allows the processing of large amounts of data with minimal cost to the network performance.
Therefore, the hash join is useful in a cybersecurity use case, for example, where irregular machine events are being investigated.
|
A tuple is a single row composed of one or more columns, where one column is mapped to one field of a document. For example, a tuple could be a row composed of two elements such as the document identifier and the key value of the join condition. If a document has a multi-valued field, this will generate as many tuples as there are values. |
For more term definitions, see the Glossary.
When to use a broadcast join
The broadcast join is best suited to scenarios where the child set of documents (also known as the right-side set) is small or medium (up to a few millions).
Therefore, the broadcast join is useful in a commercial use case, for example, where the sales of a small number of selected products are being observed.
When to use an index join
The index join is best suited to scenarios where the child set of documents (also known as the right-side set) is small (up to a few thousands keys).
Therefore, the index join is useful in a social graph use case, for example, where you start with one person and try to expand his/her relations.
Partitioning data
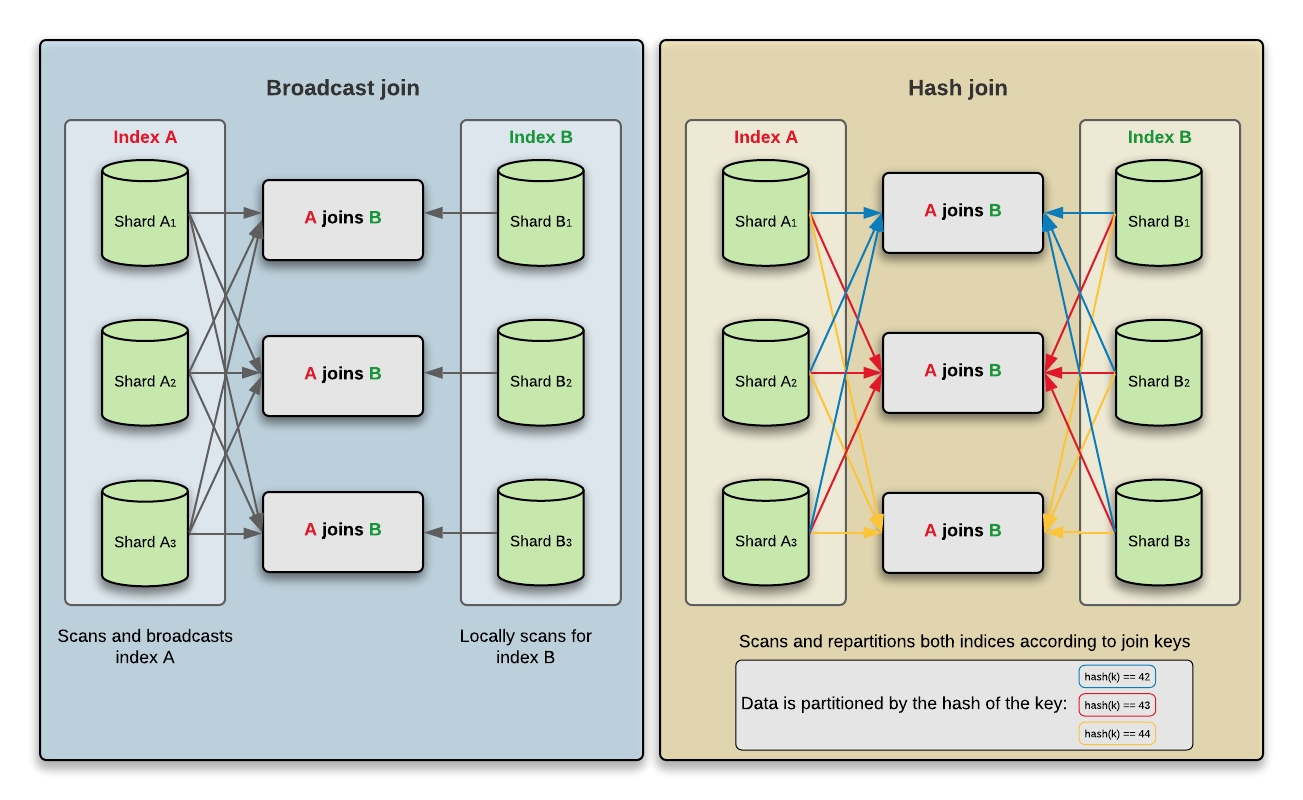
The difference between the broadcast join and the hash join lies in their approach to data partitioning.
In the following diagram, the broadcast join is shown sending data from the child set of documents (Index B) to every data node in the cluster. Therefore, each data node has the exact same input data as every other data node.
Data from the child set of documents (Index B) is sent only to data nodes that host shards of the parent set of documents (Index A). In addition, if data needs to be sent to two shards that are hosted on the same node, for example, a primary shard and a replica of Index A, then the data is sent only once to that node.
In a hash join, data from both sides is partitioned over the key and a data node receives only data with the same hash key.
To summarize, the hash join scales gracefully to process large amounts of data as the number of data nodes increases, thanks to the hash partitioning of the data.
In contrast, the broadcast and index join do not scale well because:
-
child data is duplicated across all of the nodes in the cluster, increasing network cost; and
-
a receiving node is subject to higher memory cost as the data increases.
| Join strategy | Shuffle phase (data partitioning) | Build phase | Probe phase |
|---|---|---|---|
Broadcast join |
Copies of the input data (the child set of documents) are sent to every data node. |
A in-memory hash table is built over the input data. |
The |
Hash join |
Data from both sides is partitioned over the key and a data node receives only data with the same hash key. |
An in-memory hash table is built from one of the relations in the partition. |
The second relation is scanned and each value is probed against the hash table to find matches. |
Index join |
Copies of the input data (the child set of documents) are sent to every data node. |
An in-memory hash table is built over the input data. |
Each value is probed against the dictionary of the parent set to find matches. |
Impact on performance
With a broadcast or an index join, uploading data to every data node in the cluster has an impact on the network load, the more data and nodes there are. In addition, the memory overhead on a node is linear with the size of the child set.
With the broadcast join, doc_values of the joined field of the parent set is scanned, while with the index join we perform a dictionary lookup. Indeed, with a small number of terms, the lookup is more efficient.
For this reason, the Siren Query Planner performs a cost analysis to select the more suitable join strategy.
With a hash join, apart from the network load, the fact that the data is partitioned over the cluster also has an impact on the amount of memory needed. However, the created hash table is often smaller.
|
It is possible to change the parallelization of the hash join computation by using the |
Example of the network, memory, and I/O cost of joins
A three-node cluster contains two indices with fields fieldA and fieldB, each field containing 15 million values. The field fieldA is a field from the parent set, and fieldB is a field from the child set.
In addition, each index has three primary shards and no replica. Consequently, one node has one shard of the index.
Hash and broadcast joins are two join strategies that scan the doc_values of joined fields. This scan is divided into the three categories that are most impacted:
. Network: This exhibits the cost of transferring data between nodes;
. I/O: This highlights the cost of reading data from the disk; and
. Memory: This indicates the memory requirements when joining data.
Hash join
To join both indices over fields fieldA and fieldB with the hash join, the cost would be as follows:
-
I/O cost: The system scans
doc_valuesof each index before the shuffling phase. This represents a sequential scan of 15M + 15M = 30M values or 30M / 3 = 10M per node. -
Network cost: The system shuffles each index across the available data nodes. This represents a network transfer of 15M + 15M = 30M values across the cluster.
-
Memory cost: The system stores the projected data in (off-heap) memory from both child and parent sets. The total number of values stored in memory across the cluster is 15M + 15M = 30M, since there is no duplication when compared to the broadcast join. This represents 30M / 3 = 10M values per node.
Broadcast join
To join both indices over fields fieldA and fieldB with the broadcast join, the cost would be as follows:
-
I/O cost: The system scans
doc_valuesof each index and reads 15M + 15M = 30M values from both sides of the join. -
Network cost: The system shuffles the child index across data nodes hosting shards of the parent set. This represents a network transfer of 15M * 3 = 45M values across the cluster.
-
Memory cost: The system stores the projected data in (off-heap) memory. The number of values stored in off-heap memory is 15M on each node (values from
fieldB), which are also loaded into a hash table. This represents 30M on each node, thus a total of 90M values loaded into memory across the cluster.
Index join
To join both indices over fields fieldA and fieldB with the index join, the cost would be as follows:
-
I/O cost: The system scans
doc_valuesof the child set and reads 15M values. The system also performs 15M dictionary lookups on the parent index. -
Network cost: The system shuffles the child index across data nodes hosting shards of the parent set. This represents a network transfer of 15M * 3 = 45M values across the cluster.
-
Memory cost: The system stores the projected data in (off-heap) memory. The number of values stored in off-heap memory is 15M on each node (values from
fieldB), which are also loaded into a hash table. This represents 30M on each node, thus a total of 90M values loaded into memory across the cluster.
From this example, we can determine that the hash join strategy is less expensive on the system’s operations.
While the broadcast join outshines the hash join when the child index is small (since the parent index is not partitioned over the cluster), in the above case, the broadcast join does not scale very well because:
-
the child data is duplicated across all of the nodes in the cluster, increasing network cost; and
-
a receiving node is subject to higher memory cost as the data increases.
In contrast, the hash join scales gracefully to process large amounts of data as the number of data nodes increases, thanks to the hash partitioning of the data.
Before you begin
-
Firstly, for both the broadcast and hash join strategies, you must enable
doc_valuesfor the joined fields. For the index join, only the join field of the child set requiresdoc_valuesto be enabled.Fields that have
doc_valuesenabled use a columnar data structure for storage, which Siren Federate leverages for efficient scanning.If
doc_valuesare not enabled, the join fails, stating that the field was not indexed withdoc_values. -
Secondly, ensure that the data type of the joined fields across index patterns is the same. For example, if you try to join a field from the pattern
index*, but the field is an integer inindex1while it is a keyword inindex2, an error will result. The following primitive data types are supported:-
keyword
-
long
-
integer
-
double
-
float
-
short
-
half_float
-
byte
-
date
-
IP
-
binary
-
boolean
-
Procedure
At query time, specify the join type by entering either HASH_JOIN, BROADCAST_JOIN or INDEX_JOIN in the type parameter of the join query.
For more information, see Query DSL.
The search API allows you to execute a search query and get back search hits that match the query. For example, use the following request:
`
curl -XGET 'http://localhost:9200/siren/<INDEX>/_search'
`
You can apply a join query and specify the join type that you want to use. For example, the following query specifies a hash join as its type:
curl -H 'Content-Type: application/json' -XGET 'http://localhost:9200/siren/target_index/_search' -d '
{
"query" : {
"join" : {
"type": "HASH_JOIN",
"indices" : ["source_index"],
"on" : ["foreign_key", "id"],
"request" : { (1)
"query" : {
"terms" : {
"tag" : [ "aaa" ]
}
}
}
}
}
}
'| 1 | The search request that will be used to filter out the source set (that is, the source_index). |
For more information about the join query, see Query DSL.